Data Explorer for 19th and 20th Century Brewery Business Directories
[Adapted from From BlueSky thread, March 2026]
A lot of great posts recently on this topic of "vibe coding as enabler," including the two linked here:
- https://lincolnmullen.com/blog/behind-ahead/
- https://jasonheppler.org/2026/03/09/vibing-digital-history/
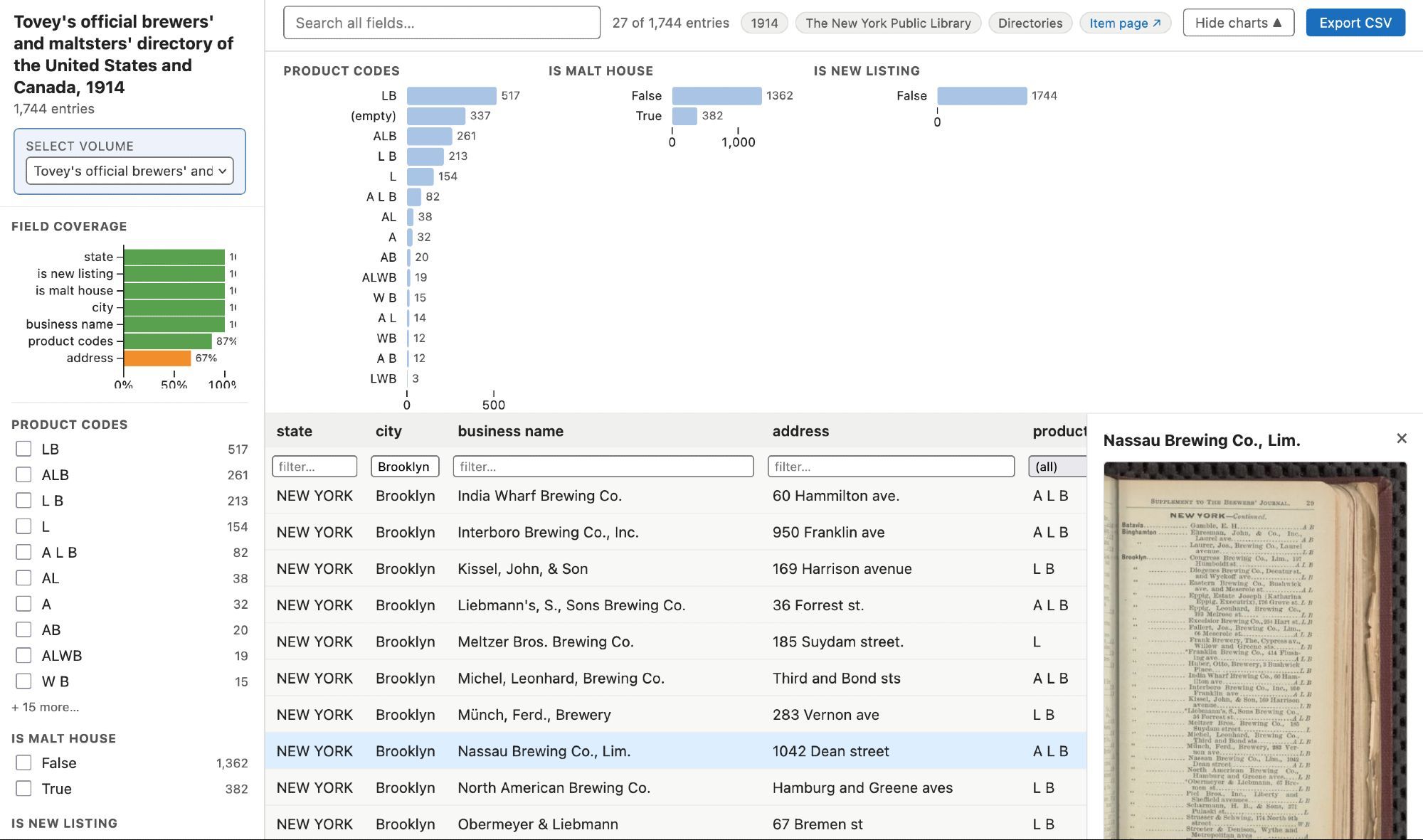
For me it's manifested as a way to scratch a digital project itch I've had for a decade, a data explorer for a set of Brewery directories from 1896 - 1918: https://hadro.github.io/brewery-guides/explorer#about
I created a github repo in 2016 to store the data from these amazing directories: digitalcollections.nypl.org/collections/...
But once I got through the OCR and PDF creation process for all the volumes, I lost steam.
With a couple of new tools, I got to where I wanted to get in a matter of hours.
On the way to building a proof-of-concept data explorer for those brewery guides, I've ended up building a somewhat generic tool that can take just about any directory-like digitized volume, send it through a couple of steps, and spit out a CSV that is more than decent enough to start exploring
I can code, but coding for personal projects lost its allure for a long time. It may lose its appeal again once I get through the things I have in mind, but for the time being I'm producing things I've always wanted to see in the world and didn't have the energy to code through.
If nothing else, it makes it possible to explore the dozens of breweries that a century ago were all within a few miles of where I live!
[From a LinkedIn post, March 2026]
Each row in the data explorer corresponds to one entry in the directory, shows you the exact entry spot in the digitized text, and if you click through a IIIF viewer will take you to the exact right spot on the primary source page.
It isn't perfect by any means — there are still some OCR or alignment errors. It's not meant to be a 100% surrogate for the content of the directories. But it seems like a valuable modern access point to the richness of this kind of resource, and probably more intuitive to most people than browsing through pages of a text item from the 19th century. If a tool like this prompts people to engage with the original digital collection item even just a little bit more than they otherwise would, that seems like a win.
For the pipeline itself, I'm using a two-pass OCR sequence: Surya OCR mainly just for bounding boxes, then Gemini for very high accuracy OCR, and then doing a multi-pass matching step to align the accurate text with the right lines — inspired by and using the algorithm in this paper.
The Data Explorer is part of a larger Directory Pipeline tool I'm working on that takes any IIIF manifest or collection as input, and works through a series of steps to output structured data like this Data Explorer view, a map view, and more.